Section 2 - Training
Last lecture, we talked about the model architecture for large language models (e.g., the Transformer). In this lecture, we will discuss how to train large language models.
Objective functions
Section titled Objective functionsWe will consider objective functions for the three types of language models:
- Decoder-only (e.g., GPT-3): compute unidirectional contextual embeddings, generate one token at a time
- Encoder-only (e.g., BERT): compute bidirectional contextual embeddings
- Encoder-decoder (e.g., T5): encode input, decode output
We can use any model that maps token sequences into contextual embeddings (e.g., LSTMs, Transformers):
Decoder-only models
Section titled Decoder-only modelsRecall that an autoregressive language model defines a conditional distribution:
We define it as follows:
- Map
to contextual embeddings . - Apply an embedding matrix
to obtain scores for each token . - Exponentiate and normalize it to produce the distribution over
.
Succinctly:
Maximum likelihood.
Let
Let
There’s more to say about how to efficiently optimize this function, but that’s all there is for the objective.
Encoder-only models
Section titled Encoder-only modelsUnidirectional to bidirectional. A decoder-only model trained using maximum likelihood above also produces (unidirectional) contextual embeddings, but we can provide stronger bidirectional contextual embeddings given that we don’t need to generate.
BERT. We will first present the BERT objective function, which contains two terms:
- Masked language modeling
- Next sentence prediction
Take the example sequence for natural language inference (predict entailment, contradiction, or neutral):
There are two special tokens:
: contains the embedding used to drive classification tasks : used to tell the model where the first (e.g., premise) versus second sequence (e.g., hypothesis) are.
Using our notation from the previous lecture, the BERT model is defined as:
where
for tokens left of , and for tokens right of .
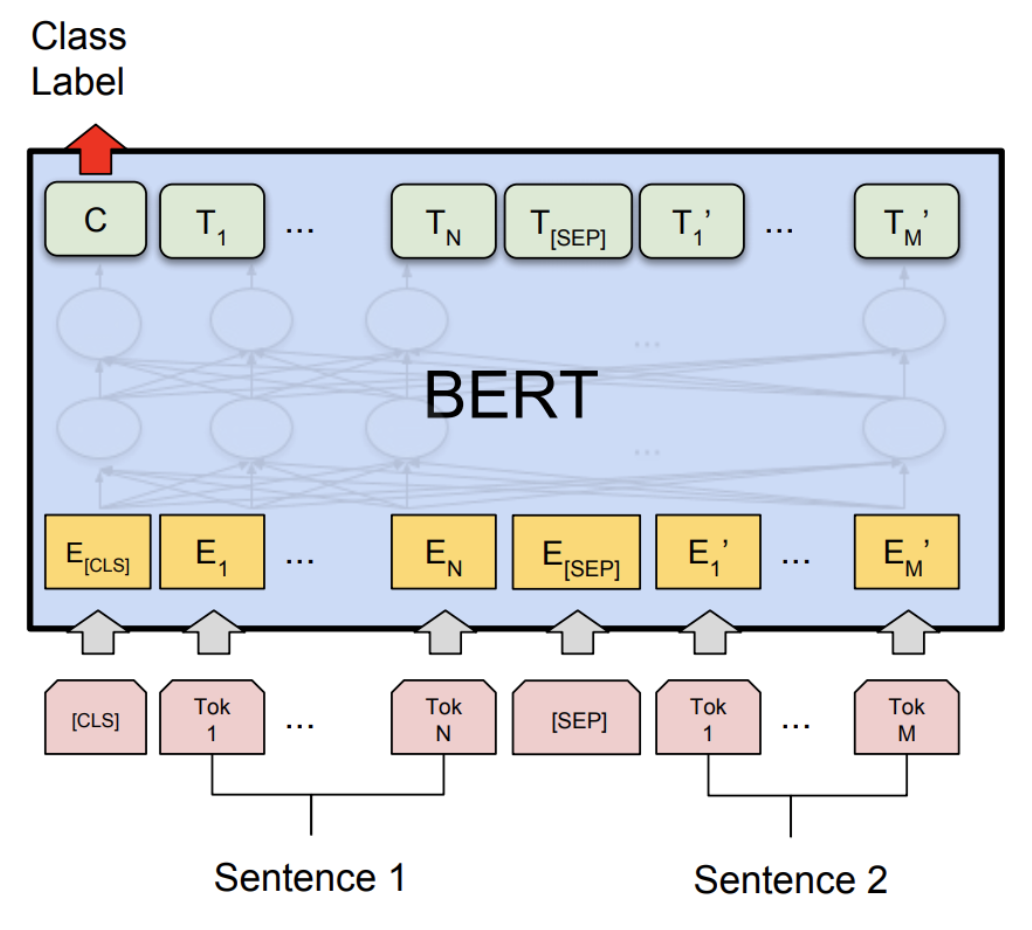
BERT-large has
Masked language modeling. The basic idea of the masked language model is to train on the prediction problem:
More more generally, we can think of this as similar to a denoising autoencoder
where we map a noisy / incomplete version
Model.
We first define the model distribution that takes
Masking function.
We define a (stochastic) noising function
Here’s how
- Let
be a random 15% of the tokens positions. - For each
:
- With probability 0.8, set
. - With probability 0.1, set
. - With probability 0.1, set
.
Reducing distribution shift.
If we were to always replace chosen tokens in
- During training, every input BERT would only see sequences with a
. - At test time, we would feed in sentences with no
, resulting in a distribution shift. The heuristic fix is to replace with real words 20% of the time.
Next sentence prediction. Recall that BERT is trained on pairs of sentences concatenated. The goal of next sentence prediction is to predict whether the second sentence follows from the first or not.
We will use the embedding of the
Dataset.
Let
- Let
be a sentence from the corpus. - With probability 0.5, let
be the next sentence. - With probability 0.5, let
be a random sentence from the corpus. - Let
. - Let
denote whether is the next sentence or not.
Objective. Then the BERT objective is:
We will talk about training later, but a few quick notes about BERT:
- BERT (along with ELMo and ULMFiT) showed that one uniform architecture (Transformer) could be used for many multiple classification tasks.
- BERT really transformed the NLP community into a pre-training + fine-tuning mindset.
- BERT showed the importance of having deeply bidirectional contextual embeddings, although it’s possible that model size and fine-tuning strategies make up for it (p-tuning).
RoBERTa makes the following changes to BERT:
- Removed the next sentence prediction objective (found it didn’t help).
- Trained on more data (16GB text
160GB text). - Trained for longer. RoBERTa improved accuracy significantly over BERT on various benchmarks (e.g., on SQuAD 81.8 to 89.4).
Encoder-decoder models
Section titled Encoder-decoder modelsExample task (table-to-text generation):
Recall that encoder-decoder models (e.g., BART, T5):
- Encode the input bidirectionally like BERT.
- Decode the output autoregressively like GPT-2.
BART (Bidirectional Auto-Regressive Transformers). BART (Lewis et al. 2019) is a Transformer-based encoder-decoder model.
- Same encoder architecture as RoBERTa (12 layers, hidden dimension 1024).
- Trained on same data as RoBERTa (160GB text).
BART considers the following transformations 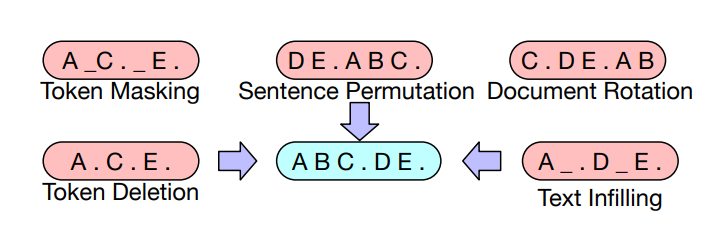 Based on BERT-scaled experiments, they decided on the following transformations
for the final model:
Based on BERT-scaled experiments, they decided on the following transformations
for the final model:
- Mask 30% of tokens in a document
- Permute all sentences
They demonstrated strong results on both classification and generation tasks using fine-tuning.
T5 (Text-to-Text Transfer Transformer).
T5 (Raffel et al., 2020) is another Transformer-based encoder-decoder model.
Tasks:
- Given a span of text, split at random point into input and output:
This paper experimented with many different unsupervised objectives:
 and found that the “i.i.d. noise, replace spans” worked well
(though many objectives were similar).
and found that the “i.i.d. noise, replace spans” worked well
(though many objectives were similar).
They also cast all classical NLP tasks in a uniform framework as “text-to-text” tasks:
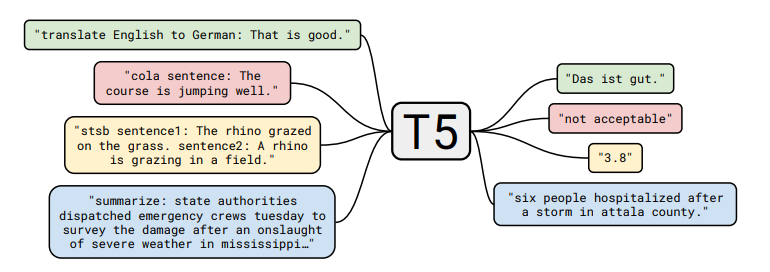 Note the difference in approach to classification tasks:
Note the difference in approach to classification tasks:
- BERT used the embedding of the
token to predict. - T5, GPT-2, GPT-3, etc. (models that can generate) cast the classification tasks in a natural language space.
Notes:
- The paper does a thorough study of many aspects of the entire pipeline (dataset, model size, training objective, etc.).
- Based on the insights, they trained a 11B parameter model.
Optimization algorithms
Section titled Optimization algorithmsNow we turn our attention to how to optimize the objective. For simplicity, let’s take autogressive language modeling:
Stochastic gradient descent (SGD). A first cut is just to do stochastic gradient descent with mini-batches:
- Initialize parameters
. - Repeat:
- Sample a mini-batch
. - Perform a gradient step:
- Sample a mini-batch
The key concerns in optimization are:
- We want
to converge quickly to a good solution. - We want the optimization to be numerically stable.
- We want to be memory efficient (especially for large models). These are often at odds with each other (e.g., fast convergence and cutting down on memory by low-precision produces less stable training).
There are several levels that we can approach optimization:
- Classic optimization: second-order methods, constrained optimization, etc.
- Machine learning: stochastic methods, implicit regularization + early stopping
- Deep learning: initialization, normalization (changes to the model architecture)
- Large language models: stability issues, weird learning rates While some of the intuitions (e.g., second-order methods) are still useful, there are many other unique challenges that need to be overcome for large language model training to work. Unfortunately, much of this is fairly ad-hoc and poorly understood.
ADAM (adaptive moment estimation). ADAM incorporates two ideas:
-
Use momentum (keep on moving in the same direction).
-
Have an adaptive (different) step size for each dimension of
(inspiration from second-order methods). -
Initialize parameters
. -
Initialize moments
. -
Repeat:
- Sample a mini-batch
. - Update parameters as follows.
- Sample a mini-batch
Updating parameters.
- Compute gradient:
- Update first- and second-order moments:
- Do bias correction:
- Update parameters:
Memory.
Using Adam increases the amount of storage from
AdaFactor (Shazeer & Stern, 2018) was proposed as a way to reduce this memory footprint.
- Instead of storing the moments (
) of a matrix, store row and column sums ( memory) and reconstruct the matrix. - Remove momentum.
- It was used to train T5.
- It can be difficult to get AdaFactor to train (see Twitter thread and blog post).
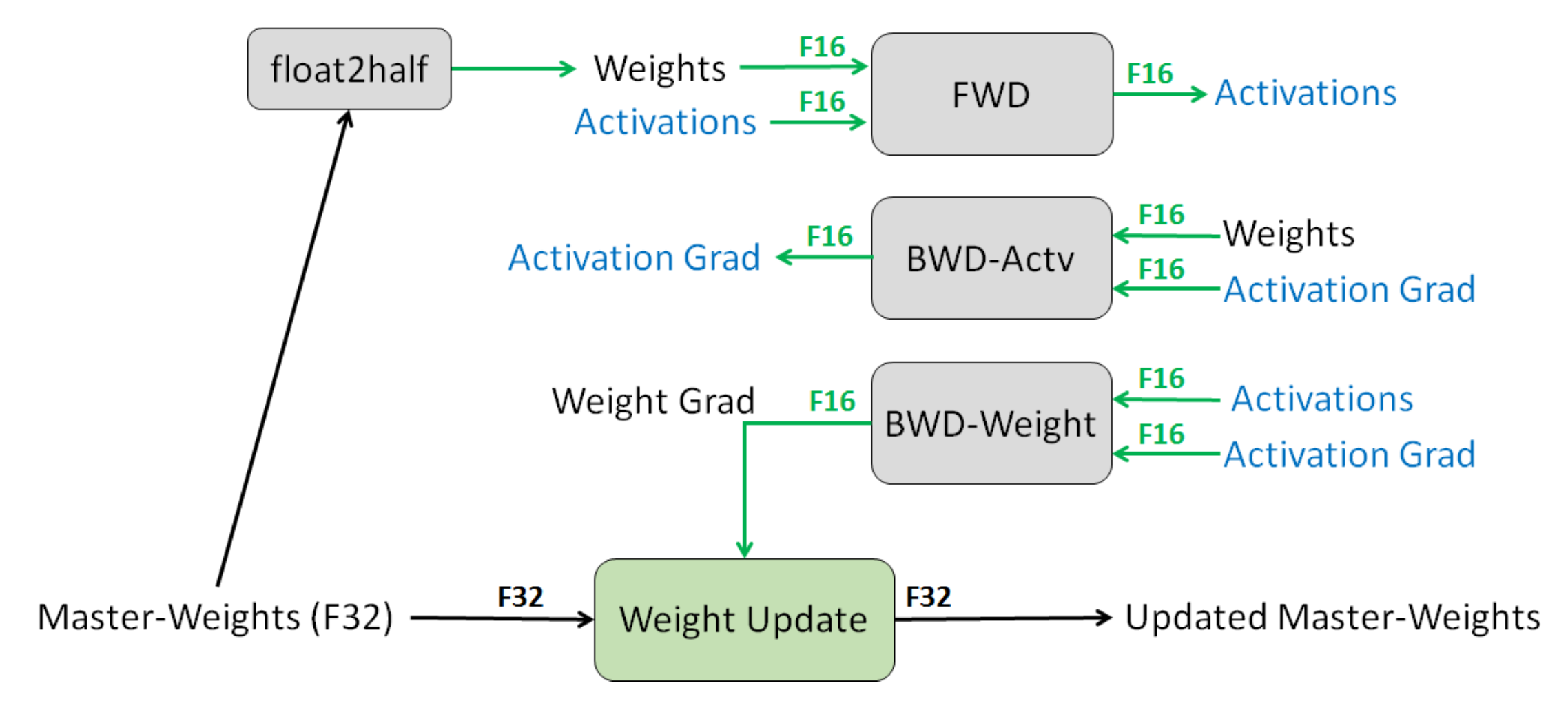
Mixed-precision training is another method for reducing memory (Narang et al., 2018).
- Default: FP32 (32-bit floating point).
- Option: FP16 (16-bit floating point), but the problem is that any value less than
becomes 0. - Solution: store master weights in FP32 and do everything else in FP16.
- Loss scaling: scale up loss to avoid gradients with small magnitudes.
- Result: Halves the memory usage.
Learning rates.
- Normally, the learning rate decreases over time.
- For Transformers, we actually need to increase the learning rate (warmup).
- Huang et al., 2020 show that a potential reason for this is to prevent vanishing gradients from layer normalization leads to instability in Adam optimizer.
Initialization.
- Given a matrix
, the standard initialization (xavier initialization) is , where is the fan-in. - GPT-2 and GPT-3 scale the weights by an additional
, where is the number of residual layers. - T5 scales the attention matrices by an additional
(code).
For GPT-3:
- Adam parameters:
, , . - Batch size: 3.2 million tokens (~1500 sequences)
- Use gradient clipping (
). - Linear learning rate warmup (over first 375 million tokens).
- Cosine learning rate that goes down to 10% of value.
- Gradually increase the batch size.
- Weight decay 0.1.
Further reading
Section titled Further reading- Mixed precision training
- Fixing Weight Decay Regularization in Adam. I. Loshchilov, F. Hutter. 2017. Introduces AdamW.
- ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning. ICLR 2020.
- DeBERTa: Decoding-enhanced BERT with Disentangled Attention. Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen. ICLR 2020.