第二节:大型语言模型的能力
我们将探索GPT-3,即典型的大型语言模型的能力。我们将紧密遵循GPT-3论文中的基准,包括:
- 标准NLP基准(例如,问答),以及
- 奇特的一次性演示(例如,在句子中使用一个新词)。
与每项任务的最新技术结果相比,结果参差不齐:
- 在某些任务上,如语言建模,GPT-3以巨大优势超过了最新技术。
- 在其他任务上,GPT-3与那些使用大量标记数据训练的系统竞争时,却远远落后。
对这些结果的思考方式如下:
- GPT-3没有明确针对这些任务进行训练;它只是被训练为一个语言模型来预测下一个词。
- 尽管没有“尝试”,GPT-3在广泛的NLP任务上平均做得还不错。
- 因为GPT-3没有针对这些任务进行训练,所以它没有过拟合,这意味着它有很大机会在许多其他任务上表现良好(如一次性任务的及格表现所示)。
- 此外,如果你想在任何特定任务上表现好(例如,问答),原则上你应该能够使用大量标记数据适应性GPT-3 来超越最新技术。
适应性。
回想一下,一个语言模型
它也可以用来在给定提示的情况下执行条件生成一个完成:
一个任务是从输入到输出的映射。例如,对于问答,我们可能有:
输入:Burne Hogarth创立了哪所学校? 输出:视觉艺术学院
我们使用适应性这个词来指代将语言模型转化为任务模型的过程,前提是:
- 任务的自然语言描述,以及
- 一组训练实例(输入输出对)。
执行适应性有两种主要方式:
- 训练(标准监督学习):训练一个新模型,将输入映射到输出,可以通过
- 创建一个使用语言模型作为特征的新模型(探测),或
- 从语言模型开始,并根据训练实例更新它(微调),或
- 中间的东西(轻量级微调)。
- 提示(上下文学习):构建一个提示(基于描述和训练实例的字符串)或一组提示,将这些输入到语言模型中以获得完成。
- 零次学习:训练示例的数量是0
- 一次学习:训练示例的数量是1
- 少次学习:训练示例的数量很少
我们应该选择哪种适应性程序?
- 由于过拟合,训练可能具有挑战性(想象一下基于5个示例微调一个175亿参数模型)。如何有效做到这一点将是适应性讲座的主题。
- 现在,我们将满足于使用提示适应性GPT-3。 注意,提示的局限性在于我们只能利用少量训练实例(可以适应性提示的实例数量)。这是由于Transformer的限制,提示和完成必须适应性2048个标记。
GPT-3论文在大量任务上评估了GPT-3。 我们将考虑其中的一个子集,并对每个任务讨论以下内容:
- 定义:任务是什么以及它的动机是什么?
- 适应性:我们如何通过提示将任务简化为语言建模?
- 结果:与特定任务的最新技术模型相比,量化数字是什么?
大小和示例数量很重要。 默认情况下,结果将基于
- 完整的GPT-3模型(davinci),它有1750亿参数
- 使用尽可能多的上下文学习训练实例来填充提示。
在此过程中,我们将进行消融研究,看看模型大小和上下文训练实例的数量是否重要。 剧透:它确实重要,而且更多是更好的。
任务分为以下几组:
本次讲座的目标是提供:
- NLP任务的概述(独立于大型语言模型),
- GPT-3表现如何的感觉,以及
- 提示工程艺术的体验。
语言建模
段落标题 语言建模思考语言模型能做什么的最自然起点是问它是否能做语言模型本应做的事情:建模语言。
回想一下,语言模型
我们可以问:语言模型赋予它的概率是多少?
回想一下,我们可以通过链式法则将联合概率分解为每个标记的条件概率的乘积:
困惑度。 序列的联合概率取决于其长度,并且随着长度的增加而趋近于零, 这使得追踪变得困难。(想想看,通过获取更多的新闻专线来获得更好的困惑度估计。)
直观地说,我们想要平均每个标记的概率
困惑度可以被解释为每个标记的平均“分支因子”。
回想一下
两种错误的故事。 语言模型可能犯两种错误,困惑度以不对称的方式对待它们:
- 召回错误:语言模型未能在某些标记上赋予概率质量。困惑度毫不留情:
- 精确度错误:语言模型在一些不良序列上赋予了额外的概率质量。困惑度提供了轻微的惩罚。
给定语言模型
,假设我们将一些垃圾分布 以概率 混合进去:
然后我们可以在
其中最后一个近似等式适用于
现在让我们开始在实际数据集上评估困惑度。
宾夕法尼亚大学树库
段落标题 宾夕法尼亚大学树库宾夕法尼亚大学树库 是 NLP 中的经典数据集, 最初是为了句法解析而注释的。 从 Emami 和 Jelinek (2004) 和 Mikolov 和 Zweig (2012) 开始, 只包含《华尔街日报》文章的数据集被用作语言建模评估。 请注意,PTB 语言建模基准涉及对原始数据集的一些重要预处理(感谢 John Hewitt 指出这一点)。
适应性。 将整个文本作为提示输入到 GPT-3 中并评估困惑度 (演示):
Pierre Vinken, 61 years old, will join the board as a nonexecutive director Nov. 29. Mr. Vinken is chairman of Elsevier N.V., the Dutch publishing group.
结果。 GPT-3 的表现远远超过了现有的最新技术:
| 模型 | 困惑度 |
|---|---|
| GPT-3 | 20.5 |
| BERT-Large-CAs1 | 31.3 |
查看 排行榜 了解最新结果。
训练/测试泄露。作者没有在某些数据集上进行评估,例如 WikiText-103 因为 GPT-3 在 Wikipedia 上进行了训练。 PTB 有提前于互联网的优势, 并且只能通过付费许可获得。 这是大型数据集的另一个复杂性: 很难检查你的测试数据是否出现在你的训练数据中并被记忆。
- 任务:预测句子的最后一个词。
- 动机:解决任务需要建模长距离依赖。
适应性。
- LAMBADA 本身已经是语言建模任务,所以我们可以直接要求 语言模型完成句子的最后一个词。
- 问题:语言模型不知道它应该生成句子的最后一个词。
- 解决方案:更明确地将其框架为输入输出映射,并使用上下文学习与额外示例 (演示):
填空:
Alice was friends with Bob. Alice went to visit her friend Bob.
She held the torch in front of her. She caught her breath. “Chris? There’s a step.” “What?” “A step. Cut in the rock. About fifty feet ahead.” She moved faster. They both moved faster. “In fact,” she said, raising the torch higher, “there’s more than a step.
结果。 GPT-3 在这项任务上的表现比之前的最新技术要好得多(基于 GPT-2):
| 模型 | 困惑度 |
|---|---|
| GPT-3 (few-shot) | 1.92 |
| SOTA | 8.63 |
查看 排行榜 了解最新结果。
HellaSwag (Zellers 等人 2019)
段落标题 HellaSwag (Zellers 等人 2019)- 动机:评估模型执行常识推理的能力
- 任务:从一系列选项中选择最合适的句子完成方式
适应性。 这是一个多项选择任务, 所以我们最自然的做法是使用语言模型为每个候选答案打分,并预测“最佳”的一个 (演示:
制作蛋糕:展示了许多蛋糕棒棒糖。一位妇女和女孩正在厨房里制作蛋糕棒棒糖。他们 $(answer)
其中 $(answer) 是其中之一:
- bake them, then frost and decorate.
- taste them as they place them on plates.
- put the frosting on the cake as they pan it.
- come out and begin decorating the cake as well.
如何给定问题
-
未归一化概率:
。未归一化概率的问题在于 它对短答案有偏见(演示)。 -
长度归一化概率:
。 这修正了长度偏见。 然而,对于两个长度相同的答案,模型仍然可能更喜欢更流行的实体。
结果。 GPT-3 接近但没有超过最新技术:
| 模型 | 准确率 |
|---|---|
| SOTA | 85.6 |
| GPT-3 | 79.3 |
然而,SOTA 在 HellaSwag 训练集上使用了微调,所以 GPT-3 能够在没有任何特定任务训练数据的情况下接近这一点, 这是非常令人印象深刻的!
查看 排行榜 了解最新结果。
问答
段落标题 问答现在我们考虑(闭卷)问答,输入是一个问题,输出是一个答案。语言模型必须以某种方式“知道”答案 而不需要在数据库或一组文档中查找信息(我们将在后面考虑阅读理解,那里提供信息)。
输入:Burne Hogarth创立了哪所学校? 输出:视觉艺术学院
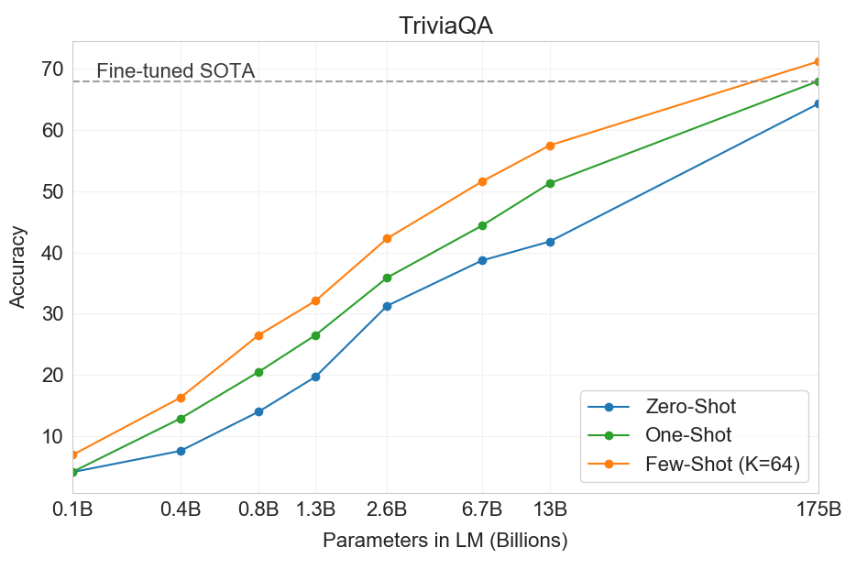
TriviaQA (Joshi 等人 2017)
段落标题 TriviaQA (Joshi 等人 2017)- 任务:给定一个趣味问题,生成答案
- 最初的数据集是从趣味爱好者那里收集的,被呈现为用于(开卷)阅读理解的挑战,但我们将其用于 (闭卷)问答。
适应性。 我们根据训练实例(如果有的话)和问题定义提示,并把完成的内容作为预测的答案 (演示):
Q:‘Nude Descending A Staircase’或许是哪位20世纪艺术家最著名的画作? A:马塞尔·杜尚
结果。
| 模型 | 准确率 |
|---|---|
| RAG | 68.0 |
| GPT-3 (zero-shot) | 64.3 |
| GPT-3 (few-shot) | 71.2 |
我们还看到增加模型大小和上下文训练实例的数量都有帮助:
WebQuestions (Berant 等人 2013)
段落标题 WebQuestions (Berant 等人 2013)- 任务:回答问题
- 数据集来自谷歌搜索查询,最初是为基于知识库的问答创建的
适应性。
我们像上面那样定义提示 (演示):
Q:Burne Hogarth创立了哪所学校? A:视觉艺术学院
结果。
| 模型 | 准确率 |
|---|---|
| RAG | 45.5 |
| GPT-3 (zero-shot) | 14.4 |
| GPT-3 (few-shot) | 41.5 |
NaturalQuestions
段落标题 NaturalQuestions- 任务:回答问题
- 数据集来自谷歌搜索查询(有长篇答案)
适应性。 我们像上面那样定义提示 (演示):
Q:谁在《天使之触》中扮演了苔丝? A:Delloreese Patricia Early (1931年7月6日 - 2017年11月19日),专业上称为Della Reese。
结果。
| 模型 | 准确率 |
|---|---|
| RAG | 44.5 |
| GPT-3 (zero-shot) | 14.6 |
| GPT-3 (few-shot) | 29.9 |
翻译
段落标题 翻译- 任务:将源语言(例如,德语)的句子翻译为目标语言(例如,英语)的句子
- 机器翻译自20世纪60年代以来一直是自然语言处理(NLP)中长期存在的任务, 统计机器翻译在2000年代在NLP中兴起(拥有自己独特的子社区),随后是2015年左右的神经机器翻译。 由于人类翻译者的存在,这一直是一个数据丰富的领域。
- 标准评估数据集是 WMT’14 和 WMT’16 数据集。
- 由于存在多种可能的翻译,(自动)评估指标是BLEU(它捕捉了n-gram重叠的概念)。
适应性。 对于少样本设置,我们构建一个包含输入输出训练实例的提示,以及输入 (演示):
Mein Haus liegt auf dem Hügel. = My house is on the hill. Keinesfalls dürfen diese für den kommerziellen Gebrauch verwendet werden. = In no case may they be used for commercial purposes.
--绝不允许这些用于商业目的。--
结果。 以下是德语到英语的结果:
| 模型 | 准确率 |
|---|---|
| SOTA (监督学习) | 40.2 |
| GPT-3 (零样本) | 27.2 |
| GPT-3 (少样本) | 40.6 |
- 即使没有监督训练数据,GPT-3也匹配了完全监督系统的技术水平!
- 这为机器翻译中能做得多好提供了一个下限; 你肯定想利用大量的平行语料库(对齐的输入输出对)。
- 来自法语和罗马尼亚语的结果类似。
- 从英语到外语的结果要糟糕得多,这是预期的,因为GPT-3主要是一个英语语言模型。
算术
段落标题 算术GPT-3 是一个语言模型(主要是英文),但我们可以在一系列更“抽象推理”的任务上评估它, 以评估 GPT-3 作为一个通用模型的性能。
- 任务:进行算术运算(2-5 位加法、减法、乘法)
- 你没有实际的理由想要解决这个任务;这只是一个诊断任务,以满足我们的科学好奇心。
适应性。 将问题作为问答提出(演示):
Q:556 加上 497 等于多少? A:1053
结果。
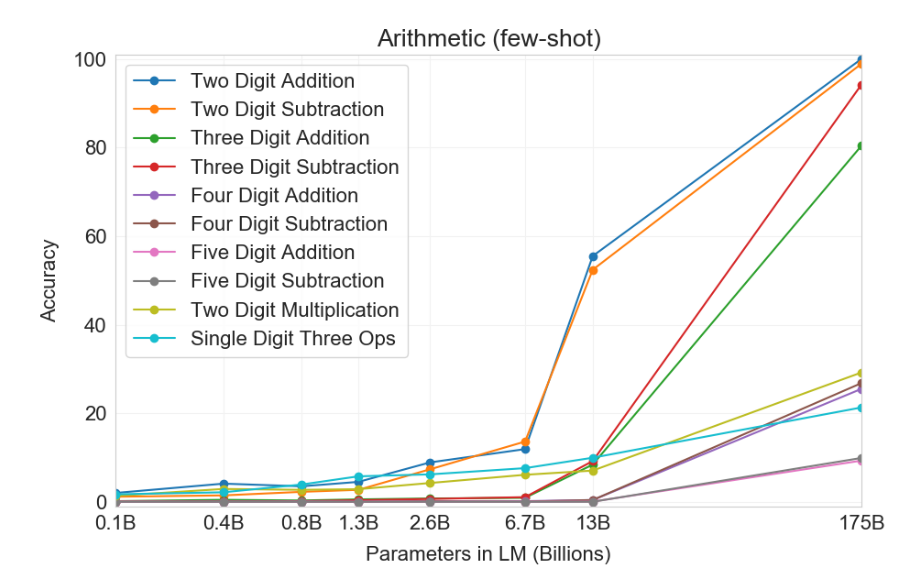
它并不完美,也很难说它完全“理解算术”,但它的表现令人惊讶地好。
新闻文章生成
段落标题 新闻文章生成- 任务:给定标题和副标题,生成一篇新闻文章
- 数据集:从 newser.com 取得的标题/副标题
- 评估:基于文章可能是由机器编写的可能性,人类对文章进行了评分
适应性。 注意:需要上下文学习,以便给模型一个提示看起来是什么样子的概念。
标题:United Methodists Agree to Historic Split 副标题:Those who oppose gay marriage will form their own denomination 文章:经过两天的激烈辩论,联合卫理公会同意进行历史性的分裂 - 据《华盛顿邮报》报道,这一分裂预计将导致一个新教派的产生,这个教派将是“在神学和社会层面上保守的”。参加该教会年度大会的大多数代表在5月投票决定加强对LGBTQ牧师的禁令,并制定新规则,以“惩戒”主持同性婚礼的牧师。但反对这些措施的人有了一个新计划:他们说他们将在2020年之前形成一个独立的教派,称他们的教会为基督教卫理公会…
结果。 人类只能52%的时候正确区分“人类”与“机器”所写(略高于随机概率)。
对于上述文章,人类正确猜测“机器”写的只有12%的时候。
新任务
段落标题 新任务使用新词
段落标题 使用新词- 任务:给定一个新造的词和它的定义,生成一个使用这个词的句子。
适应性。 在提示中描述任务 (演示):
将“screeg”某物意味着向它挥剑。使用“screeg”这个词的一个例句是: 我们用剑screeged了那棵树。
纠正英语语法
段落标题 纠正英语语法- 任务:给定一个语法错误的句子,生成它的正确版本。
适应性。 提示由输入输出对组成 (演示):
Poor English input: I eated the purple berries. Good English output: I ate the purple berries. Poor English input: Thank you for picking me as your designer. I’d appreciate it. Good English output: Thank you for choosing me as your designer. I appreciate it. Poor English input: The mentioned changes have done. or I did the alteration that you requested. or I changed things you wanted and did the modifications. Good English output: The requested changes have been made. or I made the alteration that you requested. or I changed things you wanted and made the modifications. Poor English input: I’d be more than happy to work with you in another project. Good English output: I would be happy to work with you on another project.
其他任务
段落标题 其他任务自原始论文发表以来,GPT-3已被应用于更多任务,包括基准数据集和一次性演示。以下是不完全列表。
基准测试。
- SWORDS: 词汇替换,目标是在句子的上下文中预测同义词。
- Massive Multitask Language Understanding: 包含57个多项选择题,涵盖数学、美国历史、计算机科学、法律等。
- TruthfulQA: 由于误解,人类会错误回答的问题回答数据集。
在这些基准测试上的表现仍然是中等水平,但考虑到我们正在进行少次学习,也许不算太坏!
演示。
这些演示富有创造性且有趣,但很难判断它们的可靠性如何。
总结
段落标题 总结- GPT-3 在广泛的标准 NLP 基准测试和奇特的一次性任务上进行了评估。
- GPT-3 可以表现得非常出色,也可以非常平庸。
- 增加模型的大小和示例的数量都有助于提高性能。
- 有一些启发式的方法可以调整语言模型以适应性感兴趣的任务。
- 为什么这样做有效?没有人知道。
拓展阅读
段落标题 拓展阅读- 语言模型是少次学习者 Language Models are Few-Shot Learners. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, J. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, T. Henighan, R. Child, A. Ramesh, Daniel M. Ziegler, Jeff Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei. NeurIPS 2020.
- 博客文章解释困惑度 Blog post explaining perplexity