第二节:训练
我们已经讨论了大型语言模型(例如,Transformer模型)的模型架构。 在这节内容中,我们将讨论如何训练大型语言模型。
目标函数
段落标题 目标函数我们将考虑三种类型语言模型的目标函数:
- 仅解码器(例如,GPT-3):计算单向上下文嵌入,一次生成一个词汇单元
- 仅编码器(例如,BERT):计算双向上下文嵌入
- 编码器-解码器(例如,T5):编码输入,解码输出
我们可以使用任何将词汇单元序列映射到上下文嵌入的模型 (例如,LSTMs、Transformer模型):
仅解码器模型
段落标题 仅解码器模型回想一下,自回归语言模型定义了一个条件分布:
我们按以下方式定义它:
- 将
映射到上下文嵌入 。 - 应用嵌入矩阵
以获得每个词汇单元的分数 。 - 将其指数化并规范化,以产生
的分布。
简洁地表示为:
最大似然。
设
设
关于如何有效优化这个函数,还有更多要说的,但目标函数就是这些。
仅编码器模型
段落标题 仅编码器模型从单向到双向。 使用上述最大似然训练的仅解码器模型也会产生(单向的)上下文嵌入, 但我们可以在不需要生成时提供更强的双向上下文嵌入。
BERT。我们将首先介绍BERT目标函数,它包含两个部分:
- 遮蔽语言模型
- 下一句预测
以自然语言推理的示例序列为例(预测蕴含、矛盾或中立):
有两个特殊的词汇单元:
:包含用于推动分类任务的嵌入 :用于告诉模型第一个序列(例如,前提)与第二个序列(例如,假设)的位置。
使用我们之前讲座中的符号,BERT模型定义为:
其中
- 对于
左边的词汇单元, , - 对于
右边的词汇单元, 。
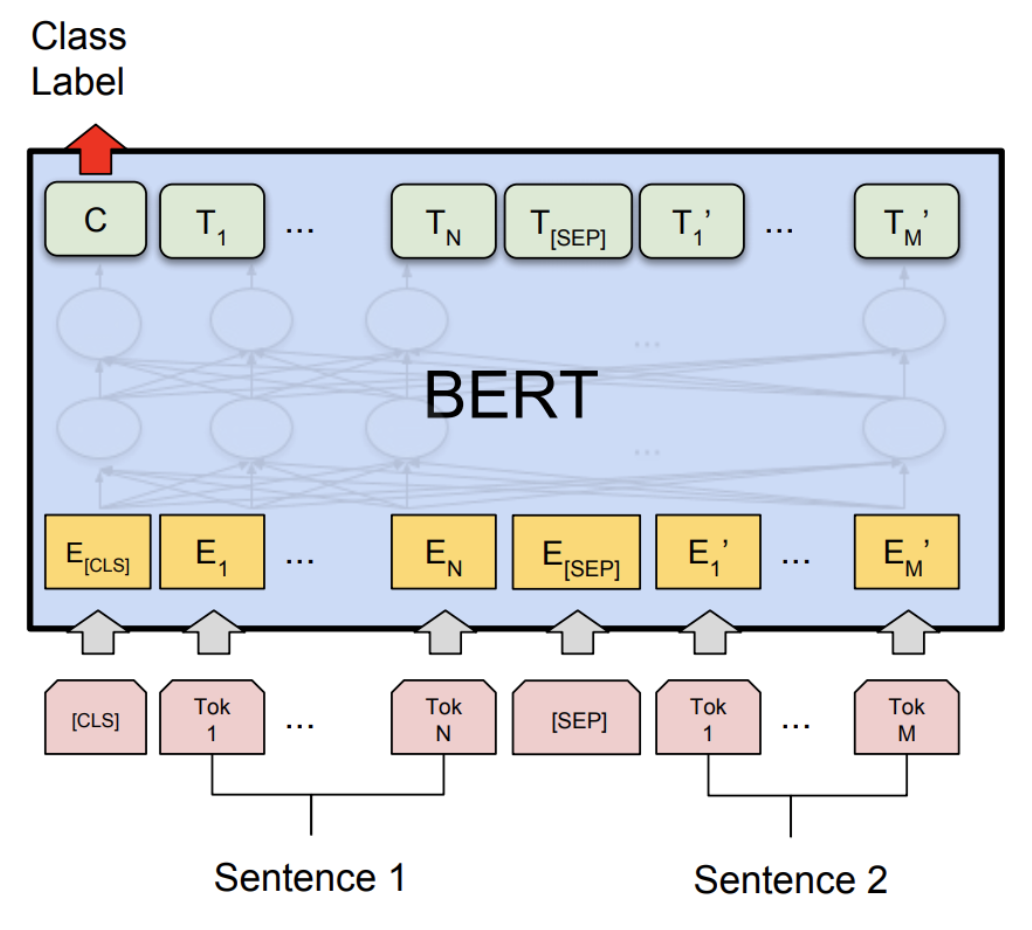
BERT-large有16个注意力头,以及1024维模型
遮蔽语言模型。 遮蔽语言模型的基本思想是在预测问题上进行训练:
更一般地,我们可以将其视为类似于去噪自编码器,其中我们映射一个嘈杂的/不完整的版本
模型。
我们首先定义模型分布,它采用
掩蔽函数。
我们定义一个(随机的)噪声化函数
这是如何定义
- 假设
是随机的15%的词汇单元位置。 - 对于每个
:
- 以0.8的概率,设置
。 - 以0.1的概率,设置
。 - 以0.1的概率,设置
。
减少分布偏移。
如果我们总是用
- 在训练期间,BERT看到的每个输入都只有
。 - 在测试时,我们将输入没有
的句子, 导致分布偏移。 启发式修复方法是20%的时间用真实词替换。
下一句预测。 回想一下,BERT是在连接的句子对上进行训练的。 下一句预测的目标是预测第二个句子是否来自第一个句子。
我们将使用
数据集。
设
- 假设
是来自语料库的句子。 - 以0.5的概率,让
是下一句。 - 以0.5的概率,让
是语料库中的随机句子。 - 设置
。 - 让
表示 是否是下一句。
目标。 然后BERT目标函数是:
我们稍后将讨论训练,但关于BERT的一些快速笔记:
- BERT(连同ELMo和ULMFiT) 表明一个统一的架构(Transformer)可以用于许多多个分类任务。
- BERT真正将NLP社区转变为预训练 + 微调的心态。
- BERT展示了深度双向上下文嵌入的重要性, 尽管模型大小和微调策略可能弥补了这一点(p-tuning)。
RoBERTa对BERT做了以下更改:
- 去除了下一句预测目标(发现它没有帮助)。
- 在更多数据上训练(16GB文本
160GB文本)。 - 训练时间更长。 RoBERTa在各种基准测试上显著提高了BERT的准确性 (例如,在SQuAD上从81.8提高到89.4)。
编码器-解码器模型
段落标题 编码器-解码器模型示例任务(表格到文本生成):
回想一下编码器-解码器模型(例如,BART, T5):
- 像BERT一样双向编码输入。
- 像GPT-2一样自回归解码输出。
BART(双向自回归Transformer)。 BART (Lewis 等人,2019) 是基于Transformer的编码器-解码器模型。
- 编码器架构与RoBERTa相同(12层,隐藏维度1024)。
- 在与RoBERTa相同的数据上训练(160GB文本)。
BART考虑了以下转换 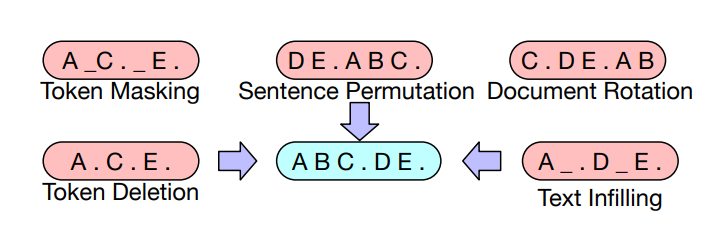 基于BERT规模的实验,他们为最终模型选择了以下转换:
基于BERT规模的实验,他们为最终模型选择了以下转换:
- 遮蔽文档中30%的词汇单元
- 排列所有句子
他们通过微调,在分类和生成任务上展示了强大的结果。
T5(文本到文本转换Transformer)。
T5 (Raffel 等人,2020) 是另一个基于Transformer的编码器-解码器模型。
任务:
- 给定一段文本,在随机点将其分割为输入和输出:
这篇论文尝试了许多不同的无监督目标:
 并发现“独立同分布噪声,替换跨度”效果很好
(尽管许多目标相似)。
并发现“独立同分布噪声,替换跨度”效果很好
(尽管许多目标相似)。
他们还将所有经典NLP任务统一框架为“文本到文本”任务:
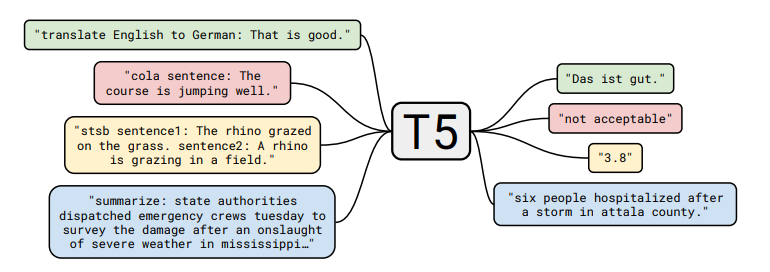 注意分类任务方法的不同:
注意分类任务方法的不同:
- BERT使用
词汇单元的嵌入来预测。 - T5, GPT-2, GPT-3 等(可以生成的模型)将分类任务置于自然语言空间。
笔记:
- 论文对整个流程的许多方面进行了彻底的研究(数据集、模型大小、训练目标等)。
- 基于这些见解,他们训练了一个11B参数模型。
优化算法
段落标题 优化算法现在我们转向如何优化目标。 为了简单起见,让我们采用自回归语言建模:
随机梯度下降(SGD)。 首先,只需使用小批量的随机梯度下降:
- 初始化参数
。 - 重复:
- 采样一个小批量
。 - 执行梯度步骤:
- 采样一个小批量
优化中的关键问题:
- 我们希望
能快速收敛到一个好的解决方案。 - 我们希望优化在数值上稳定。
- 我们希望内存效率高(特别是对于大型模型)。 这些通常相互矛盾 (例如,快速收敛和通过低精度减少内存会产生不太稳定的训练)。
我们可以从几个层面来接近优化:
- 经典优化:二阶方法、约束优化等。
- 机器学习:随机方法、隐式正则化 + 提前停止。
- 深度学习:初始化、归一化(模型架构的更改)。
- 大型语言模型:稳定性问题、奇怪的学习率。 尽管一些直觉(例如,二阶方法)仍然有用, 但对于大型语言模型训练来说,还有许多其他独特的挑战需要克服。 不幸的是,这些大多相当临时且理解不足。
ADAM(自适应性矩估计)。 ADAM结合了两个想法:
-
使用动量(保持同一方向前进)。
-
对
的每个维度有自适应性(不同)的步长(来自二阶方法的启发)。 -
初始化参数
。 -
初始化矩
。 -
重复:
- 采样一个小批量
。 - 按以下方式更新参数。
- 采样一个小批量
更新参数。
- 计算梯度:
- 更新一阶和二阶矩:
- 进行偏差校正:
- 更新参数:
内存。
使用Adam增加了存储量从
AdaFactor (Shazeer & Stern, 2018) 被提出作为减少内存占用的方法。
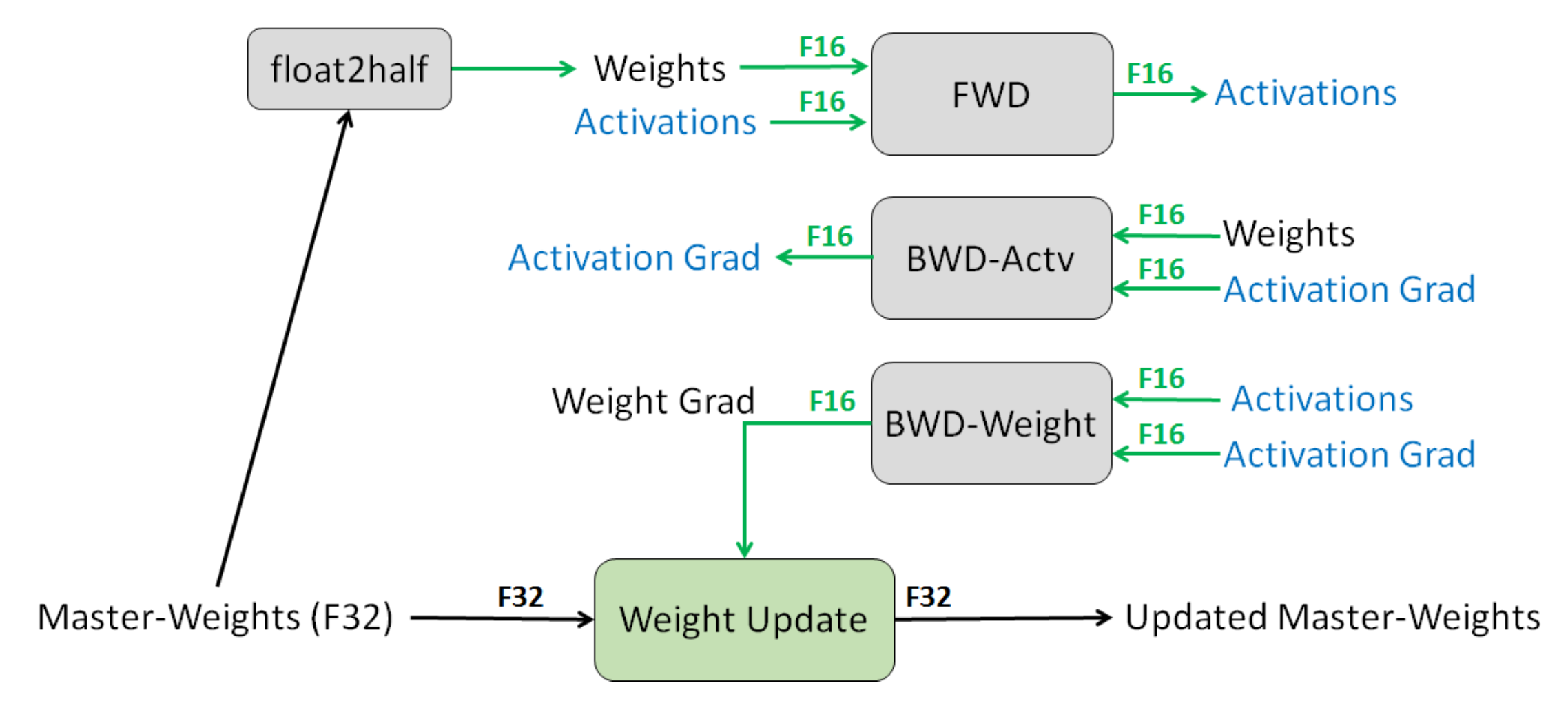
混合精度训练是另一种减少内存的方法 (Narang 等人,2018)。
- 默认值:FP32(32位浮点)。
- 选项:FP16(16位浮点),但问题是任何小于
的值都会变成0。 - 解决方案:以FP32存储主权重,其余部分使用FP16。
- 损失缩放:放大损失以避免幅度很小的梯度。
- 结果:内存使用减半。
学习率。
- 通常,学习率随时间减少。
- 对于Transformer,我们实际上需要增加学习率(预热)。
- Huang 等人,2020表明 这可能是为了防止 层归一化导致的梯度消失,从而导致Adam优化器不稳定。
初始化。
- 给定一个矩阵
,标准初始化(xavier初始化)是 ,其中 是输入单元数。 - GPT-2和GPT-3通过额外的
对权重进行缩放,其中 是残差层的数量。 - T5通过额外的
对注意力矩阵进行缩放(代码)。
对于GPT-3:
- Adam参数:
, , 。 - 批量大小:300万个词汇单元(约1500个序列)。
- 使用梯度裁剪(
)。 - 线性学习率预热(在前3.75亿个词汇单元)。
- 余弦学习率降至其值的10%。
- 逐渐增加批量大小。
- 权重衰减0.1。
拓展阅读
段落标题 拓展阅读- 混合精度训练
- 在Adam中修复权重衰减正则化。I. Loshchilov, F. Hutter。2017。 引入了AdamW。
- ELECTRA:作为鉴别器而非生成器预训练文本编码器。Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning。ICLR 2020。
- DeBERTa:带有解耦注意力的解码增强BERT。Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen。ICLR 2020。